A számítógépes nyelvészet kulisszatitkai
Nyelvészportrék XVI. Beszélgetés Prószéky Gáborral
Az interjút Daniss Győző készítette.
Ha hét-nyolc évtizede az átlagember azt olvasta, hallotta, hogy komputer, számítógép, nemigen gondolhatott másra, mint hogy létezik egy ördöngös szerkezet, ami tud osztani, szorozni, százalékot számítani, és talán még köbgyököt vonni is képes. A nyelvről „általában” pedig elsősorban azt tudta, hogy van angol meg német meg kínai. S az iskolai tanulmányokból azt is, hogy a magyar ragozó nyelv, és ragozáskor megkülönbözteti egymástól az ikes meg az iktelen formát. Azóta a számítógép és a nyelv fogalma közel került egymáshoz. A sokféle programmal feltöltött műszaki csodák az asztali számítógéptől a tableten, a laptopon keresztül az okostelefonig sokunk mindennapos használati eszközévé lettek. Hatással vannak, lehetnek írásunkra, beszédünkre, s immár a nyelvészek tudományos munkájához is nélkülözhetetlenek. Hogy a közelkerülés miképpen történt, és miképpen történt Magyarországon, arról kérdéseinkre Prószéky Gábor mondta el a legfontosabbakat.
– Hogy a computer – hiszen akkor még nem született meg a számítógép szavunk – a nyelvvel is kapcsolatba kerülhet, azt az amerikai hadsereg mérnökei vetették fel a második világháború idején. A katonai kódolás ismert volt, és úgy tűnt akkoriban, hogy a fordítás is egyfajta kódolási feladat. És mindezek a tennivalók a hidegháború éveiben sem vesztették el a fontosságukat. Az Egyesült Államok a hatvanas évek derekáig nagyon sok pénzt fektetett be elsősorban az orosz és az angol nyelv közötti gépi fordító rendszerek fejlesztésébe. Az akkori hatalmas – még lyukszalagos, lyukkártyás – gépek arra már jók voltak, hogy megtalálják egy-egy kiválasztott szó más nyelvű megfelelőit. De hiányoztak azok a szoftverek, amik szükségesek lettek volna ahhoz, hogy a gép a kikeresett szavakból a tartalmat híven visszaadó mondatokat alkosson. E próbálkozások sikertelensége miatt az USA 1966-ban be is szüntette a gépi fordítások kutatásának, fejlesztésének nagy léptékű támogatását.

– E miatt a „visszalépés” miatt azonban – a mából visszatekintve úgy sejlik – a gépi fordítás ügye nem került le a tudományos-technikai világ szakembereinek napirendjéről…
– Egyáltalán nem került le! Ugyanis eközben, már az ötvenes években, az elméleti nyelvészet is felfigyelt a számítógép kínálta lehetőségekre. Korábban a nyelvészek főként a nyelv, a nyelvek múltját kutatták. A XX. században azonban megélénkült érdeklődésük a nyelvek jelene, „maga a nyelv” iránt. Nem utolsósorban az eredetileg matematikus, amerikai generatív nyelvész, Noam Chomsky hatására. Szerinte léteznek a nyelvekre nemcsak önmagukban, hanem univerzálisan is érvényes működési elvek. A Szovjetunióban az idő tájt szintén jó néhány tehetséges nyelvész dolgozott. Ők az egymástól eltérő formai megoldásokat használó nyelvek matematikai összehasonlításával próbálták a nyelvek összességének közös törvényszerűségeit felfedezni. És úgy esett, hogy az egyik ilyen nyelv az agglutináló, tehát toldalékoló magyar lett.
– Volt-e ennek a kiválasztásnak magyarországi hatása?
– Az ötvenes évek végén, a hatvanas évek elején nyelvészekből és matematikusokból, számítógépes szakemberekből megalakult egy munkacsoport, hogy megszülessen egy orosz–magyar gépi fordítási program. Tudva, hogy a gép nem lesz képes műfordítói szintű szövegeket alkotni, de remélve, hogy a „gépfordítások” segíthetik az „emberfordításokat”.
– Egy fordításnak, persze, alapkérdése, hogy valamely szónak abban az aktuális szövegbeli helyzetben mi a megfelelője a másik nyelven…
– Ezt a feladatot a számítógépes és nyelvész szakembereknek csak részben sikerült megoldaniuk. Ma már bárki hozzáférhet olyan számítógépes szótárakhoz, amelyek szavak sokaságát száznál is több nyelven „tudják”. Sőt, némelyik nyelven nemcsak leírják, hanem ki is mondják. És nemcsak világnyelvekről vagy Európában gyakori nyelvekről van szó, hanem olyanokról is, mint a dél-afrikai xhosa, az indiai gudzsaráti vagy a haiti kreol. De hogy mikor melyik jelentésben áll valamelyik szó, az bizony a szövegkörnyezettől függ.
Nyelvtudományi és matematikai módszerek
A Magyar Nagylexikon 2001-ben megjelent 12. kötete nem önálló szócikkben, hanem a „matematikai nyelvészet” szócikk részeként ismerteti az akkor rendelkezésre álló legfontosabb „tudni illőket”.
A számítógépes nyelvészet „…nyelvtudományi ágazat, amely nyelvtudományi módszerek és modellek formalizálására törekszik. Matematikai módszereket használ nyelvészeti elméletek pontosítására, illetve ilyen elméletek formális tulajdonságainak megállapítására, az elmélet formális következményeinek felderítésére. A matematikai nyelvészethez tartozik: […] 3. a számítógépes nyelvészet, amely egyrészt a statisztikai és algebrai nyelvészet számítógépes alkalmazásaival, másrészt a nyelvi struktúrák számítógépes modellálásával, illetve a nyelvi viselkedés (elemzés, generálás, illetve megértés, produkció) szimulálásával foglalkozik; főbb alkalmazási területei: gépi fordítás, számítógépes szótárkészítés (számítógépes lexikográfia), számítógépes információszerző rendszerek (szövegmegértő, illetve szövegkivonatoló rendszerek, párbeszédes rendszerek) kifejlesztése, mesterségesintelligencia-kutatás.”
– A szavak megfeleltetésétől hogy juthatnak el a programok szószerkezetek mondatrészek, mondatok megfeleltetéséig?
– Nehezen. Kiváltképpen azért, mert a mondatok szerkezete különféle nyelveken más és más. Hiába tud jól angolul egy program, fordításkor nagyon gyakran beleütközhet a másik nyelvnek – akár még a németnek, svédnek, dánnak vagy különösképpen az orosznak – az angolétól különböző valamely sajátosságába. Még nehezebb a fordítás, ha egy szerkezetében gyökeresen különböző nyelven kell megtalálni az eredetivel azonos értékű megoldást.
Ilyen gyökeresen más nyelv – az angolhoz, némethez, svédhez, dánhoz s a más vonatkozásban már említett oroszhoz képest – a toldalékoló magyar. Amit nálunk egyetlen szó fejez ki, azt nem agglutináló nyelvek gyakran csak több szóval, esetleg egy egész mondattal tudják csak elmondani. Például egy ilyen szó: elnézegethetném.
Könnyíti a gépi fordítást – bármelyik nyelvpár esetében –, hogy bizonyos esetekben már nemcsak szavak, hanem szószerkezetek, sőt akár egész mondatok is benne vannak a fordítórendszer adatbázisában. És az sem lehetetlen, hogy egy ritka, mondjuk svéd–bolgár szövegáttevést két lépcsőben oldjanak meg a gépek. Ilyenkor a svédet előbb valamilyen „közvetítő” nyelvre – a gyakorlatban sokszor angolra – fordítják, utána pedig az angolt bolgárra. Ahogyan ez az úgynevezett relézés soknyelvű konferenciákon „embertolmácsolásnál” is gyakorlat.
– A toldalékolás nemcsak fordításkor okozhat nehézséget, olykor magunknak is akadhatnak vele gondjaink. Hiszen: Bécs-ben, de Pécs-en, vagy akár Pécs-ett. Hogy boldogulnak az ilyen esetekkel a magyar nyelvű programok?
– Az ezzel foglalkozóknak – ezt a MorphoLogic cég számítógépes nyelvészeti tevékenységének vezetőjeként magam is tapasztalhattam – tengernyi fáradságába került, hogy megtanítsák a gépeket efféle feladatok megoldására. Az olyan egyedi helyzetekben, amelyekre nincs szabály, csak rögzült valamiféle hagyomány – mint az említett városnevek toldalékolása esetében –, viszonylag könnyű volt a megoldás: egy az egyben megadtuk a gépnek az adott városhoz illő toldalékot.
A magyar hangtan és szóalaktan szabályait megfogalmazhatjuk a programok nyelvén, és akkor jól fogja kezelni a különböző közneveket is, mint a ház-on, repülőgép-en, gyümölcs-ön, golyó-n. Tehát a gép „megtanítható” arra, hogy valamely általa addig nem ismert szóhoz is – annak magánhangzójára, magánhangzóira tekintettel – az „-on”, az „-en”, az „-ön” és az „-n” vagy a „-hoz”, a „-hez” és a „-höz” közül melyik ragot illessze. Tehát ha valaki, például egy nyelvtanuló azt írja, hogy virágcserép-ön vagy virágcserép-hoz, akkor a gép felhívja a figyelmet a rossz toldalékolásra, és akár javasolja is a helyes alakot: virágcserép-en, virágcserép-hez.
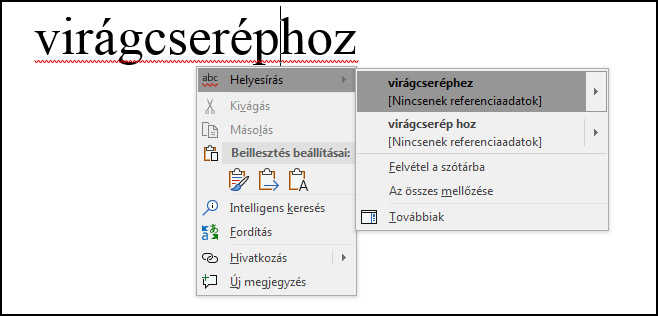 "a gép felhívja a figyelmet a rossz toldalékolásra, és akár javasolja is a helyes alakot"
"a gép felhívja a figyelmet a rossz toldalékolásra, és akár javasolja is a helyes alakot"
Beszédet generál a gép
Kolozsi Ádámnak az É. Kiss Katalinnal készített – A magyar nyelv logikája külföldön is érdekes című – interjújában a professzor asszony egyebeken kívül a számítógépnek az írott szöveggel és a hangzó beszéddel való viszonyáról beszélt:
„Nem hiszem, hogy az egyik nyelv könnyebben algoritmizálható, mint a másik. Van persze, ami az angolban könnyű, például ott nem nagyon van morfológia. A magyarban Papp Ferenc számításai szerint egy főnévnek 714 lehetséges alakja van (házaimból, házatoknak stb.), de hiába sok, ha egy nyelv jól le van írva – és a magyar elég jól van leírva –, ez azért elég könnyen algoritmizálható. Nagyon sokat merítenek a statisztikából is: ha van egy 500 millió szavas korpuszunk, ami megvan magyarul és angolul is, akkor a számítógépes nyelvészek rengeteg kész fordulatot, mondattöredéket tudnak használni.
Ami nagyon jó nálunk, az a számítógépes beszédgenerálás, már észre sem vesszük, hogy automata beszél a telefonban vagy a hangosbemondóban. A beszédfelismerés egy kicsit nehezebb, könnyebb az írott beszédet hangzóvá tenni, mint a hangzót írottá, de szerintem ezekben jól állunk, és ha többet finanszíroznának, még jobban állnánk.”
– A mindennapi gyakorlatból kiviláglik, hogy a gép nemcsak toldalékolási hibákat jelez…
– Igen, kiszűr másféle hibákat is. Legalábbis a többségüket. Nem maradhat jelzetlenül a kájha, a malyom, a budapest, a szántófld, a bürökrata. Ezekben az esetekben is ajánlhatja a jó megoldást. A programok a maguk ismeretkörükön belül azt is tudják, hogy két vagy több szót egybe, külön vagy kötőjellel kell-e írni. Ez nem mindig könnyű, még a helyesírási szabályokat nagyon alaposan ismerő embernek sem. És ilyesmikben természetesen nemcsak mi tévedhetünk vagy bizonytalankodhatunk, hanem a gép is. Egy „gyanús” mondatban a legjobb program is zavarba jöhet. Egyik kedvencem az, hogy „A magyar ember evés közben nem beszél” mondat esetében – mert a gép óriási szövegtárában benne van az „emberevés” szó is – a program például felvet egy szerinte jobb lehetőséget: „A magyar emberevés közben nem beszél”.
– Mi történik a nyilvánvaló tévedések eseteiben? Ha valaki például azt írta: „1256-ban zajlott le a mohácsi csata”, vagy azt, hogy „Deák Lajos a haza bölcse”…
– A helyesírási programoknak nincs kulturális háttérismeretük, a számok értelmezésével pedig általában nem tudnak mit kezdeni. A gép tehát nemcsak a mohácsi évszámhoz nem nyúl, hanem azt sem jelzi, hogy valami nincs rendben, ha valamely szöveg szerint napjaink piacán, mondjuk, 24 vagy épp 2400 forintért árulják a krumpli kilóját. A „Deák Lajos” is legfeljebb csak akkor kaphatna esetleg figyelmeztetést egy speciálisan arra a célra írt programtól, ha a szövegben már nagyon sokszor előfordult a „Deák Ferenc” – de ez továbbra sem helyesírási kérdés.
Nehéz helyzetben van viszont a gép az olyan esetekben, amikor hasonló nevek közül kell választania – főképpen, ha csak a vezetéknevet látja: „Széchényi”, „Széchenyi”, „Szécsényi”. Hiszen egy adott szövegben általában csak az egyik név lehet helyes. A programok ebben és az ehhez hasonló helyzetekben érthető módon tanácstalanok. Jobb a helyzet, ha adott a keresztnév is, és ha a gép szövegtárában egyetlen kifejezésként megtalálható esetleg a könyvtáralapító Széchényi Ferenc, a „lánchidas” Széchenyi István és a diszkoszvető bajnok, majd egyetemi tanár Szécsényi József neve. Bonyolítja a dolgot, hogy a „szécsényi” betűsor, ha nem a mondat elején van, adott esetben kisbetűvel írandó, mert csupán jelzője a Nógrád megyei Szécsény városához kötött személynek, intézménynek, épületnek.
 Bódi Zoltán: Infoszótár
Bódi Zoltán: Infoszótár
– Hogy boldogul a gép más helyzetekben a kisbetűkkel és a nagybetűkkel?
– Általában jól. De ha egy szövegben előfordul például az, hogy valami „a XVIII. században történt”, akkor a római szám utáni pontot a nem magyar számítógépes nyelvészek által kifejlesztett szövegszerkesztő programok mondatzárónak vélik, és a passzust kijavítják: „a XVIII. Században történt” alakra. Hozzáteszem, hogy a mai programok többségét a felhasználó beállíthatja úgy, hogy hasonló esetekben hagyja meg a kisbetűs „XVIII. század” alakot. Azt azonban a szövegszerkesztő program felhasználójának kell tudnia, hogy melyik menüpontban lehet kikapcsolni az ennek a furcsaságnak az előidézőjét, a „Mondatkezdő nagybetű” opciót.
– Az ember tehát kijavíthatja, amit a gép „rosszul tud”. Persze, a gép nyilvánvalóan azért tud valamit rosszul, mert nem lehet minden különleges helyzetre felkészíteni. Különleges helyzet adódhat például sorvégeken. Hogy tudnak a gépek elválasztani?
– Az elválasztással értelemszerűleg csak a toldalékkezelő programunk elkészülte után kezdhettünk foglalkozni. A szavak java részénél egy program jól tudja alkalmazni a helyesírási szabályokat: e-me-let, meg-ma-gya-rá-zom, lám-pa-bú-ra. Jól alkalmazza egyébként a valahai helyesíráshoz szokott idősebb embereket olykor még mindig meglepő új szabályokat is: mad-zag helyett ma-dzag, mened-zser helyett mene-dzser, hiszen a „dz”-t és a „dzs”-t ma már ugyanolyan betűkapcsolatnak tekintjük, mint az „sz”-t vagy a „ty”-t.
1& mond6ok: akár szokás lehet belőle
Balázs Géza az A beszéd, írás, új beszélt nyelviség antropológiája – netnyelvészeti megközelítés című tanulmányában a számítógépen rögzített, továbbított furcsa – hajdani betűrejtvényekre emlékeztető – tartalomrögzítésekről, továbbításokról szólva Szilvási Csabának egy Kazinczy sorait („Jót s jól! Ebben áll a nagy titok”) felidéző versét hozza példának, megjegyezve, hogy „ami ma tréfa, játék, már ma is nyelvi tény, holnap akár nyelvszokássá válhat”. A vers és utána a műfajban (meg a rejtvényfejtésben) kevéssé gyakorlottaknak szóló „fordítás”:
most, ?kor az ifjak & a v* szülék
@Z: is ot van már a k&zülék,
s nM fSt ürS f&seGt a f&seg&,
mRt úr 1& a RviCSg, s a józan&z,
jó tanácsot ® csak 1& mond6ok,
SMS: is csak jót s jól írjatok.
(Most, mikor az ifjak és a vén szülék
kezében is ott van már a készülék,
s nem fest üres fecsegőt a fecsegés,
mert úr lett a rövidség, s a józan ész,
jó tanácsot én csak egyet mondhatok,
sms-ben is csak jót s jól írjatok.)
– Képes-e a program jól elválasztani olyan – alakjukban azonos, de jelentésükben különböző – betűsorokat, amilyen például a „gépelem”?
– Az elválasztó program tudja, hogy a szónak két felbontása van: gép-elem és gé-pelem. Csak nem lehet teljességgel bizonyos benne, hogy melyik jelentésűt kell az adott helyen elválasztania. Ezért ezt a szót nem választja el, meghagyva ezt a lehetőséget az embernek, ha a felhasználó mindenképp el akarná választani. De idővel akár az elválasztó programok is képesek lehetnek ilyen helyzetben is jól dönteni. Mert alaposan „megnézhetik” majd, hogy aktuálisan milyen tartalmú szövegben fordul elő a „gépelem” betűsor. Ha a szövegben határozottan felismerhetők írógépeléssel kapcsolatos más szavak, kifejezések is, akkor ezt fogja javasolni: gé-pelem. Ha pedig a szó műszaki jellegű, valamilyen szerkezet alkatrészeit soroló szövegben áll, akkor azt javasolja: gép-elem. Ugyanígy a szövegösszefüggéseket figyelembe véve dönthet a program például a le-gelőre és a leg-előre megoldás között. De az embernek mindig kontrollálnia kell a még oly okos gépet is.
 Ha az ímélemet gépelem, az elválasztás nem lehet "gép-elem"!
Ha az ímélemet gépelem, az elválasztás nem lehet "gép-elem"!
– Akkor hát – sokak felületes hitével ellentétben – nem elég a helyesírást javító szoftver, változatlanul szükség van emberi helyesírástudásra is. Miközben a számítógépet néhány tévedése, eseti tanácstalansága ellenére is tarthatjuk valamiféle három műszakos „robot-magán-magyartanárnak”, aki vagy ami nemcsak kijavítja a rosszul használt „ly”-t, „j”-t, hanem ezzel egyszersmind meg is tanítja vagy legalább megtaníthatja a helyes szóalakot…
– Arra taníthatja meg, amit az embertől megtanult. Amikor a nagy nyilvánosságnak szánt, „közhasználatra” való szöveget írunk a gépbe, akkor igyekszünk betartani a helyesírás szabályait. Jó esetben még lektor, szerkesztő vagy korrektor is megnézi a mondatokat. Ám ha magánlevelet írunk, ha valakivel számítógépen keresztül folytatunk laza „írott beszélgetést”, akkor nem okvetlenül fordítunk nagy gondot a helyesírásra. Esetleg közismert, vagy csak kettőnktől használt rövidítésekkel, sajátos szóötletekkel küldjük el társunknak a mondandónkat. És ő egy-egy nyelvileg helytelen megoldásunkat jónak, kifejezőnek találva talán maga is használni fogja. Azt az üzeneteiben akaratlanul is megismerteti másokkal. Ha aztán a „normától eltérő” szóalakot a képernyőn sokan és sokszor látják, kezdhetik azt tekinteni jónak. És a rossz szóalak, szófordulat lassanként szélesebb körben is elterjed.
A számítógép tehát – mint ahogy egy nyomtatott szöveg régebben is, ma is – nemcsak a jó, hanem a rossz megoldásokra is biztathat. Például a közelmúltban divatossá lett „csevej” szót többen és gyakran csevely formában írták le. Ezt mások helyesnek vélték, és maguk is így kezdték használni. A tévedés azon alapul, hogy a nyelvhasználók nem ismerik fel a robaj, zörej, moraj mintájára létrejött csevej-t. Ez esetben talán a „csermely” szó formai rokonságának volt szerepe a rossz alak elterjedésében. Szerencsére – az ezzel kapcsolatos kritikák okán is – mostanában mintha csökkenne az „ly”-os előfordulások száma. A csevely „népszerűsítésétől” eltekintve azt hiszem, hogy a gépre a helyesírás dolgában is sokkal inkább a pozitívumok jellemzők. Tehát: csevej!
Alakulóban egy új elnevezés
A számítógéppel, mobillal, laptoppal stb. folytatott kommunikációnak még nincs kanonizálódott hazai elnevezése. Meggondolandó javaslatok azonban már léteznek:
- digilektus (Veszelszki Ágnes)
- írott beszélt nyelv (többen használják már)
- másodlagos szóbeliség (Balázs Géza)
- szimbolikus írásbeliség (Bódi Zoltán)
- új beszéltnyelviség (Bódi Zoltán)virtuális írásbeliség (Érsek Nikoletta)
– Amikor néhány esztendeje Olaszy Gábor, a Nyelvtudományi Intézet Kempelen Beszédkutató Laboratóriumának munkatársa rekonstruálta a labor névadójának a beszélőgépét, az bizony – nyilvánvalóan a XVIII. század műszaki korlátai miatt – csupán néhány hang kiejtésére volt képes. Kempelen óta e fontos tekintetben – hiszen a kommunikációnak nemcsak az írás, hanem a beszéd is eszköze – meddig jutott a műszaki tudomány és a nyelvtudomány?
– Vannak már olyan programok – programok ma már akár egy okostelefonban is –, amelyek nemcsak hangot rögzítenek s adnak vissza, hanem arra is képesek, hogy ha írott szöveget „látnak”, azt emberi hangon felolvassák. Mégpedig nem betűnként, hiszen akkor a „felolvasás” inkább csak zörej lenne, hanem pontosan követve a betűknek az adott szóban megjelenendő valóságos hangalakját.
– Vagyis?
– Ugyanaz a leírt betű a betűkapcsolatoktól függően sokféleképpen hangozhat. Az „n”-t nem ugyanúgy mondjuk az orgona, az angol és a honvéd szóban. E különböző „n”-eket – mégpedig több embertől rögzített sokféle kiejtést „átlagolva” – mind-mind meg kell adni a programnak, hogy aztán az később az azonos hangkapcsolódási helyzetben rögzített hangmintát vegye elő.
Egy másik érdekesség, hogy a beszélőt is tudjuk már „utánozni”: a mai technikával akár Marilyn Monroe hangján is megalkothatunk egy olyan slágert, amit a művésznő sohasem énekelt. Természetesen csak akkor, ha rendelkezésünkre áll az ő néhány más dalfelvétele, és azok hangkapcsolatait megtanítjuk a programnak.
Az efféle programoknak köszönhetően már az sem csupán álom, hogy valaki az erre alkalmas gép ábécétáblájára nézve, tekintetét betűről betűre irányítva jelenítsen meg szöveget a képernyőn, s azt kinyomtassa, elküldhesse. Ma már lehetséges, hogy amit a látássérültek a maguk – esetleg Braille-betűs – klaviatúráján beírnak, azt egy másik gép Braille-írással is kinyomtassa. Hogy hallássérültek a maguk jelelését okostelefon képernyőjén továbbíthassák társuknak.
Immár az sem lehetetlen, hogy mondjuk egy magyarul elküldött szöveg a fogadó készüléken egy másik nyelvre lefordítva jelenjen meg. És ki tudja, milyen eszközöket, milyen lehetőségeket, fordulatokat hoz még a jövő…
A „gépi nyelv” hatni fog
A múlt század derekának gazdag fantáziájú jövőkutató mérnöke, Arthur C. Clarke egyebeken kívül a számítógép és a nyelv kapcsolatáról is álmodozott. Az álma – mutatják a tények – részben alul-, részben felülmúlta az azóta eltelt évtizedek valóságát:
„A számítógépekkel kapcsolatos »gépi nyelv« fejlődése kétségtelenül komoly visszahatással lesz a nyelvészetre is. Néhány tudós máris megpróbált olyan logikai nyelvet kifejleszteni, amely nem szenved  az összes meglévő nyelvben fennálló kétértelműségekben és hiányosságokban. Ez a próbálkozás sokkal becsvágyóbb, mint egy másik eszperantó vagy más nemzetközi nyelv kiagyalása, mert ez a gondolat legmélyebb alapjáig megy vissza. Bár nem hinném, hogy a logikai nyelv olyan valami, amelyben költészetet vagy szerelmes leveleket lehetne írni, fejlődését mégis szívesen látnánk. Talán a jövőben két nyelv lesz – egy a gondolkodásra és egy másik az érzelmek kifejezésére. A második lehet, hogy az emberi faj sajátsága lesz, de az első univerzális alkalmazásra találhat.”
az összes meglévő nyelvben fennálló kétértelműségekben és hiányosságokban. Ez a próbálkozás sokkal becsvágyóbb, mint egy másik eszperantó vagy más nemzetközi nyelv kiagyalása, mert ez a gondolat legmélyebb alapjáig megy vissza. Bár nem hinném, hogy a logikai nyelv olyan valami, amelyben költészetet vagy szerelmes leveleket lehetne írni, fejlődését mégis szívesen látnánk. Talán a jövőben két nyelv lesz – egy a gondolkodásra és egy másik az érzelmek kifejezésére. A második lehet, hogy az emberi faj sajátsága lesz, de az első univerzális alkalmazásra találhat.”
(Forrás: A. C. Clarke: A jövő körvonalai [1962, magyarul 1969])
– Eközben az emberi aggyal vezérelt kézírás a mindennapokban kezd visszaszorulni. Ez akár oda vezethet, hogy elfelejtjük a kézírást vagy esetleg meg sem tanulunk már tollal, ceruzával írni?
– Nagy butaság lenne lemondani a kézírásról. Nemcsak azért, mert a kézírás személyesebb a „gépi” írásnál, és vannak helyzetek, amikor ez a személyesség nagyon fontos. Hanem azért is, mert ha kézzel írunk, azzal gyakoroljuk, fejlesztjük a motorikus készségeinket.
Már 2010-ben élen volt az e-mail
Veszelszki Ágnes 2010-ben online kérdőíves felmérést készített különféle kommunikációs lehetőségek igénybevételének gyakoriságáról. A hatszáznál több válaszadó háromnegyede a 19–40 esztendős korosztályból került ki.
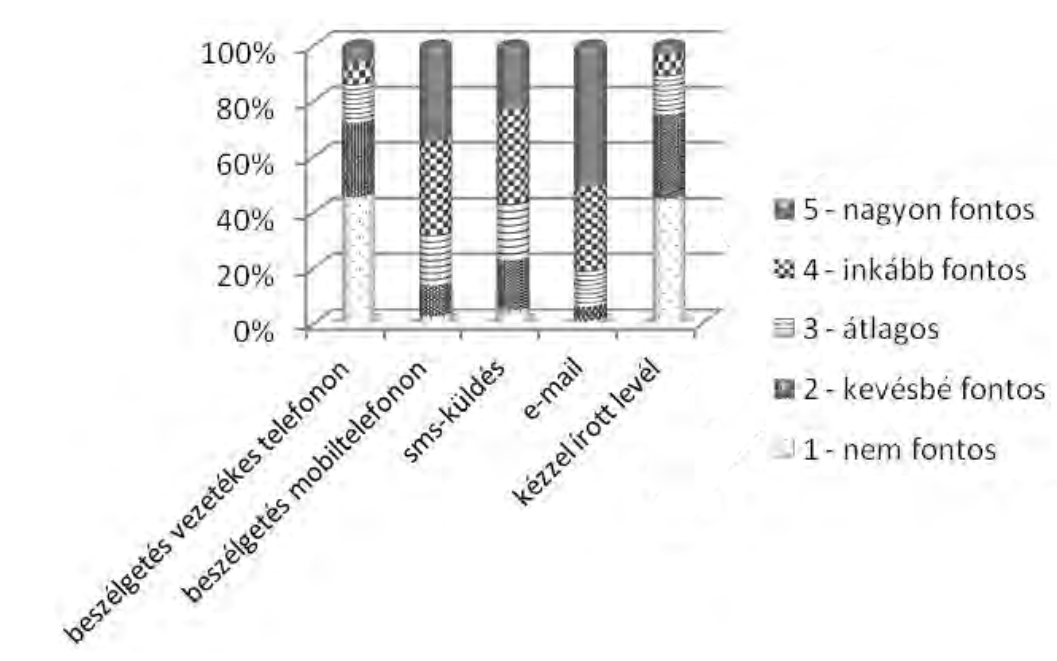
(Forrás: Veszelszki Ágnes: A digilektus hatása az írásbeli és a szóbeli kommunikációra egy kérdőíves vizsgálat alapján – Magyar Nyelvőr, 2013/3)
– Sokmilliónyian élvezhetjük már Magyarországon is a számítógépes szakemberek és a nyelvtudósok munkálkodásának gyümölcseit. És mindezektől a hardver- és szoftvercsodáktól mit kapott – vagy inkább: mit kapott vissza – a nyelvtudomány?
– Nagyon sok ismeretet és lehetőséget. Olyanokat, amelyekkel számítógépek nélkül nem élhettek volna, nem élhetnének a nyelvész szakemberek. Például: könnyen hozzáférhető lett elképesztő mennyiségű nyelvi adat, és ezek a gépi programok – hangsúlyozom, hogy ember alkotta programok – sokféle dologban nagyon gyorsan megfaggathatók.
Nemrégen – elődeink minden dicséretet megérdemlő szövegkorpuszainak létrejöttét követően – sikerült megcsinálnunk az azoknál sokszorta nagyobb Pázmány Korpuszt. Ez a több mint 1,2 milliárdos anyag majdnem 70 millió önálló mondatot tartalmaz. Van benne 403 millió főnév, 141 millió melléknév, 137 millió ige, és még római számból is van 164 ezer, kötőjelből pedig 152 ezer. Mindezeket természetesen nem egyenként kellett bevinni, hanem megfelelő programok segítségével internetes és más források magyar nyelvű anyagaiból kerültek a számítógéprendszerünkbe.
– Mifélékből?
– Főképpen különféle közelmúltbeli írott – részben szerkesztett, tehát igényesen megformált – szövegekből, részben az írott beszélt nyelv személyes szövegeiből.
– Az óriási adatszámból következik, hogy egy-egy szó több ezerszer vagy akár több tízezerszer is megjelenhet a korpuszban…
– Így van. Egy szó, persze, nemcsak egy alakban szerepel: ház, a házban, házakat, házon, műanyag ház, a kutya háza és így tovább. És ugyanaz az alak több különféle szövegkörnyezetben jelenhet meg. Például a „vár” ige is sokféle formában, más-más szavak előtt-után nagyon sokszor fordul elő. A „várt” alakot kiválasztva a képernyőn egyebeken kívül ilyen szövegeket látunk: „…levegő árad; olyasféle, amilyet már nagyon régen várt a kritika és a színház. A Rang és mód…”, és mellette egy másik szövegdarab: „…ellenezte az emigrációt is: tőle semmi jót nem várt, legfeljebb a Monarchia s vele együtt…”. A „várt” szóhoz hasonlóan a többit szintén szövegkörnyezetben adjuk vissza. És ezt a környezetet meg is hosszabbíthatjuk. Ismét hozzáteszem: egy-egy szó mindig a szövegkörnyezettől kapja meg a pontos jelentését.
Legtöbb a főnév
A Pázmány Korpusz jelenleg 1,2 milliárd szót tartalmaz (kétezerszer többet, mint a Biblia, kétszázszor többet, mint Jókai valamennyi írása, és több mint hússzor többet, mint ahány szó az Encyclopædia Britannica utolsó nyomtatott változatának 17 kötetében van). E hatalmas szógyűjteményben csupán a névelősereg is 118 milliónyinál több előfordulást számlál.
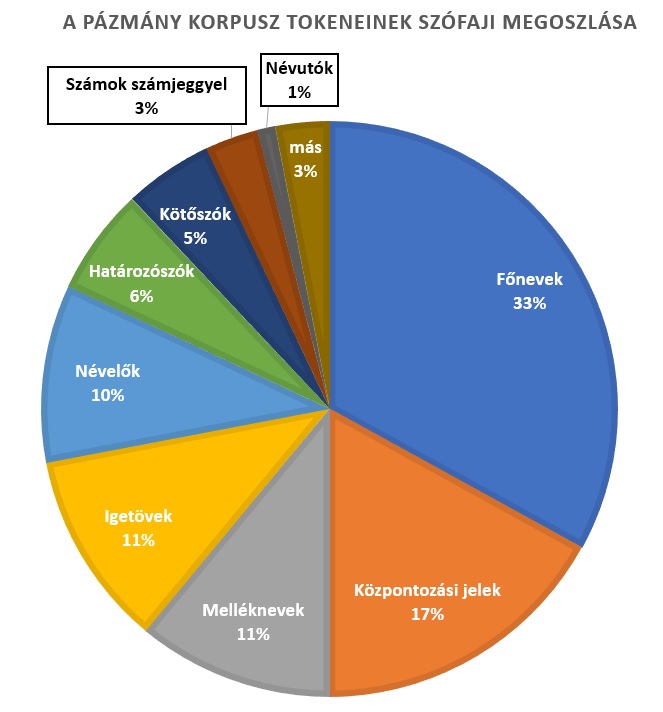
(Forrás: Endrédy István–Prószéky Gábor: A Pázmány Korpusz – Nyelvtudományi Közlemények 2016)
– Azaz egy-egy szó árnyalatnyi jelentéskülönbségeire, jelentésgazdagságára is felhívja, felhívhatja a figyelmünket?
– Többre is. Például a „hány” betűsor lehet kérdő névmás és lehet ige. Az utóbbi pedig az árnyalatnyinál nagyobb jelentéskülönbségeket is kifejezhet. Csak néhány lehetőség: valakinek a szeme szikrát hány, valaki havat hány, cigánykereket hány, epét hány, kardélre hány vagy holmikat egymásra hány, esetleg a búza már hányja a kalászát…
A Pázmány Egyetemen működő kutatócsoportomnak van olyan fejlesztése, amely arra is képes, hogy azonos alakú szavakat jelentésük szerint különböző más halmazokban mutasson meg. Az „egér” betűsor az egyik jelentésében bekerül például a patkány mellé, a „rágcsálókarámba”. A másikban, egyebeken kívül a klaviatúra mellé, a „számítógépkarámba”. A gép olyan halmazokat is megalkothat, amilyenekre az ember nem is gondol. Tengernyi névből kiválasztja például a női neveket, és abból is villámgyorsan létrehozza a régebben kedvelt nevek csoportját: Mária, Erzsébet, Teréz, vagy éppen a mai divatnevek csoportját: Cintia, Villő, Roxána, sőt azt is sejteti, hogy a Genovéva–Eulália–Skolasztika halmaz elemei rokonok, hiszen – tesszük hozzá, mi, emberek – közös vonásuk, hogy belőlük gyakran választottak maguknak nevet a valamelyik apácarendbe belépők…
 Bevezetés a korpusznyelvészetbe
Bevezetés a korpusznyelvészetbe
Néha nem is értjük pontosan, hogy a mai, úgynevezett mély tanulást végző programok hogyan képesek ilyen ismeretek kibányászására. De képesek rá. Ahogyan egy kazánházi dolgozó is pontosan tudja, hogy melyik gombot kell megnyomnia vagy melyik kart kell elfordítania, ha a műszerek ilyen vagy olyan hibát jeleznek – miközben nincsenek pontos ismeretei arról, hogy közbeavatkozására miképpen is áll helyre a kazán működése.
Egyébiránt a számítógépbe táplált programok „tudományos hozadéka” az is, hogy a nyelvész könnyebben követheti nyomon, hamarabb ismerheti fel nyelvünk nagyobb távú és napjainkbeli változásait, a „csak írott” és az „írott beszélt” nyelv azonosságait, különbségeit, egymásra hatását. E programokkal észrevehetjük a „szabad szemmel” még nem látható, akár a kanonizált szabályoktól eltérő, de a gyakorlatban már jelen lévő nyelvhasználati változásokat is.
– Túlzott derűlátás-e azt gondolni, hogy az említett tanulságokat kamatoztató újabb és újabb gépi programokkal, korszerű tankönyvekkel, nyelvművelő írásokkal, rádió- és tévéműsorokkal, nem utolsósorban pedig a számítógépes világ teljes arzenáljával gazdagabbá válhat nyelvi kultúránk? És talán még abban is hinni, hogy a mai és jövőbeni hardvereknek és szoftvereknek köszönhetően nyelvi tekintetben jobban, pontosabban megértjük majd egymást?
– Nem túlzott derűlátás: és ez már nem is a jövő, hanem a jelen…
Prószéky Gábor
Budapesten született, a Budapesti Piarista Gimnáziumban érettségizett. Egyetemi tanulmányait az Eötvös Loránd Tudományegyetem Természettudományi Kara programozó, majd programtervező matematikus szakán, és részben ezzel egy időben a Bölcsészettudományi Kar általános és alkalmazott nyelvész szakán végezte. Később több alkalommal tudományos ösztöndíjasként tanult, kutatott Finnországban és az Egyesült Államokban.
Diplomái megszerzése után tudományos ösztöndíjasként, majd munkatársként az MTA Zenetudományi Intézetében hasznosíthatta számítógépes tudását. Ott Dobszay Lászlónak, a gregorián zene világszerte elismert kutatójának munkájához kapcsolódva kidolgozott egy olyan adatbázisrendszert, amelyben tárolni – és amelyet használva elemezni is – lehetett a közép- és kelet-európai kolostorok kódexeinek gregorián énekeit, feltüntetve azok megfelelő egyházi alkalmakhoz való kötődését. Ez megteremtette a régi zene kutatásának addig nem ismert lehetőségeit. Kettejük mindezeket összefoglaló munkája, az 1988-ban megjelent Corpus Antiphonalium Officii Ecclesiarum Centralis Europae című kötet azóta is a zenetörténet kutatóinak egyik világszerte legtöbbet idézett alkotása – abban Dobszayéi voltak a gregoriánkutatási, Prószékyéi a tárgy számítógépesítés kutatásának lehetőségeit megalapozó, sok külföldi szakkutató munkáját is érdemben segítő fejezetek.
A következőkben az Országos Pedagógiai Könyvtár és Múzeum számítástechnikai osztályának tudományos főmunkatársaként, majd főtanácsadójaként könyvtár-automatizálással foglalkozott, kollégáival megalkotta az intézménynek a hagyományos „cédulaalapúnál” jóval gazdagabb tartalmú, ha úgy tetszik, „intelligens” számítógépes katalógusrendszerét.
Közben a Műszaki Könyvkiadó felkérésére megírt egy a számítógépes nyelvészetről szóló 600 oldalas kötetet, aminek köszönhetően hosszabb időt tölthetett kutatással Hollandiában.
Kandidátusi disszertációját 1994-ben, akadémiai doktori disszertációját 2005-ben védte meg. Egyetemi tanárként 2006-ban habilitált a Pázmány Péter Katolikus Egyetem Információs Technológiai és Bionikai Karán.
Közel kétszáz szaktudományos és felsőoktatási tanulmány, kötet szerzője, társszerzője; ezeket több mint félezerszer idézték tudományos munkák vagy hivatkoztak rájuk számítógépes és nyelvész szakemberek. Csak ízelítőnek a magyar nyelvű munkák közül: Számítógépes nyelvészet – Természetes nyelvek használata számítógépes rendszerekben (kandidátusi disszertáció, 1994), Számítógéppel emberi nyelven (társszerzővel, 1999), A magyar nyelvtechnológia megalapozása: a nyelvhelyesség-ellenőrzéstől a gépi fordításig (akadémiai doktori disszertáció, 2005), A számítógép, az elektronikus kommunikáció és az internet hatása (in: Tolcsvai Nagy Gábor: A magyar nyelv jelene és jövője, 2017).

Tanított az ELTE-n, és ma is tanít a PPKE Információs Technológiai Karán, annak alapítása óta folyamatosan. Több mint húsz doktorandusza szerzett tudományos fokozatot.
Mindeközben – az ő szavával – „belecsöppent a tudományból a gyakorlatba”. Megkeresték egy személyi számítógépen működtethető magyar helyesírási program dolgában. Egy munkatársával megcsinálta. A háttérben ehhez elkészült a más nyelvű programokból általában érthetően hiányzó, az agglutináló magyarban azonban nélkülözhetetlen program a toldalékolásról. Nem volt egyszerű az elválasztási program elkészítése sem. És ezeken kívül sok-sok részfeladatot is meg kellett oldani.
E megoldások többsége már az 1991-ben negyedmagával alapított MorphoLogic nevű vállalkozás keretein belül született meg. A cégnek Prószéky Gábor lett az igazgatója. Az ő irányításával teremtettek elektronikus szótárakat, dolgoztak ki angol–magyar és magyar–angol fordítási és magyar helyesírási programot. A Pázmány Péter Katolikus Egyetemen alakított kutatócsoportjával pedig létrehozta a nyelvünk kutatásában új lehetőségeket teremtő, az idő tájt hazánkban a legnagyobb ilyen típusú adatarzenált, a Pázmány Korpuszt – 1,2 milliárd szóval.
Prószéky Gábor az 1980-as évektől számos külföldi és hazai tudományos projekt résztvevője, több magyar és nemzetközi folyóirat szerkesztőbizottságának tagja. Számos tudományos testületben tevékenykedik. Közülük csak a legutóbbi évtizedből és csak a hazaiakból említve néhányat: MTA Szótári Munkabizottsága (elnök, 2007–2012), MTA–PPKE Magyar Nyelvtechnológiai Kutatócsoport (igazgató, 2012–), Neumann János Számítógép-tudományi Társaság (alelnök, 2013–2015), Magyar Nyelv Terminológiai Tanácsa (alelnök, 2013-tól), Magyar Alkalmazott Nyelvészek és Nyelvtanárok Egyesülete (elnök, 2013-tól), MTA Magyar Nyelv Osztályközi Állandó Bizottsága (elnök, 2015-től). És 2017-ben kinevezték az MTA Nyelvtudományi Intézete igazgatójának.
Kitüntetései a legutóbbi két évtizedből: Széchenyi-díj (2000), Az év informatikai menedzsere (2002), Brassai Sámuel-díj (2005), Az Év Informatikai Oktatója (2009), Gábor Dénes-díj (2010), Pázmány Plakett (2013).
Legkedvesebb saját könyve: Számítógépes nyelvészet – Természetes nyelvek használata számítógépes rendszerekben.




